 From May 5th to May 8th I attended the 3rd European Identity Conference (EIC). As a testimonial on the front page says, it was “a wonderful and informative event, well run and useful in so many ways.†(If I quote a page quoting me, is that recursion or delegation?)
From May 5th to May 8th I attended the 3rd European Identity Conference (EIC). As a testimonial on the front page says, it was “a wonderful and informative event, well run and useful in so many ways.†(If I quote a page quoting me, is that recursion or delegation?)
I attended the first two EICs and, while I greatly enjoyed them, each conference has been better than the last. EIC strikes a good balance between providing a forward looking vision of what identity management technology should provide for business, and what practical solutions are available now.
In previous years I have noticed great contention about what identity system had the best design, had the correct name, was the most open, was favored by which group, etc. I asked other vendors why there seemed to be much less of that contention this year. All of them answered that there is not much to debate; there are valid use cases for the classic federation protocols, as well as OpenID, OAuth, and information cards — and all are open standards. So we’ve all been implementing products that use these protocols. However, as the products are deployed most system designers also recognize that we are far from done. What we have available now in open standards are valid systems that are a leaps forward, but are still not sufficient – there is still more to be done to make the systems more intuitive, more usable, more functional.
I presented my thoughts on these issues in an early OASIS session. The presentation was “Gaps and Overlaps in Identity Management Solutionsâ€. The gist of the talk was that we don’t need to dumb down identity systems for people; we need to provide more intuitive, nuanced and contextual systems so that people can express the richness of relationships online. I illustrated this point with a stereotypical Granny who commonly handles delicate interactions with complex forms of indirect speech as she navigates many kinds of relationships in real life. We have too long focused on trying to make her use a single user name and password, rather than than allowing her to manage relationships. Our users do not need us to dumb down online identity systems – they need us to allow them to intuitively handle the richness of relationships. Online systems need to perform transactions within various contexts, unequal power levels, third party sources, etc. To bring the point home – so to speak – the presentation featured photos of my mom as the stereotypical Granny.
The tireless Felix saw the presentation and posted an interview with me about it.
 Over the next few days there were many presentations and lively panel discussions, including the one led by Dave Kearns and discussed in his newsletter. I greatly enjoyed participating in 3 panels and moderated a 4th. One thing I really like that seems to happen frequently at EIC is that the audience participation with a panel can get quite animated and extend into the expo area after the session.
Over the next few days there were many presentations and lively panel discussions, including the one led by Dave Kearns and discussed in his newsletter. I greatly enjoyed participating in 3 panels and moderated a 4th. One thing I really like that seems to happen frequently at EIC is that the audience participation with a panel can get quite animated and extend into the expo area after the session.
The expo also was expanded this year. What I particularly liked about Novell’s booth was that it highlighted customers and their innovative use of Novell products – it seemed much more interesting and less like a sales pitch. As always, it was good to get to meet my Novell colleagues there: Marina Walser, Ulrike Beringer, Klaus Hild, AleÅ¡ KuÄera, et al. Marina gave a great keynote (which was much discussed over the next few days, especially the customer survey results) and also recorded an interview with the ubiquitous Tim Cole.
With Marina and Ulrike, I participated in some press interviews. Being a typical unilingual American, I can’t actually read some of the resulting articles. Nevertheless, they appear to be quite interesting based on the (sometimes humorous) automatic translations.
It was a very busy week. I sometimes could only listen to part of a session before going to another commitment. One of my favorite (unfortunately partial) sessions was “Access Control in the Cloud†by André Koot. Rather than theory of identity systems or analysis of protocol families, André focused on using claims and information cards as a basis for flexible and manageable access control from an enterprise or university to cloud based services.
There were many other great discussions and presentations by visionaries and curmudgeons. Apparently attending a conference in Europe is the only way to see Jackson Shaw these days – well worth the effort.
 The final EIC highlight was particularly significant to me because it involved my new area of focus – identity and security services for Cloud Computing. On the last afternoon I led a workshop about Enterprise Identity in the Cloud. It had been a long and intense conference, so we expected light attendance and decided to keep it as just an open discussion. The best part about this was that we had a small, but tightly focused conversation with customers, systems architects, and representatives of a few vendors. It was particularly great to have Martin Kuppinger join us to share his deep insights into cloud computing, and provide some adult supervision.
The final EIC highlight was particularly significant to me because it involved my new area of focus – identity and security services for Cloud Computing. On the last afternoon I led a workshop about Enterprise Identity in the Cloud. It had been a long and intense conference, so we expected light attendance and decided to keep it as just an open discussion. The best part about this was that we had a small, but tightly focused conversation with customers, systems architects, and representatives of a few vendors. It was particularly great to have Martin Kuppinger join us to share his deep insights into cloud computing, and provide some adult supervision.
Overall, I noticed three themes at EIC this year:
- Open standards-based multi-domain identity systems are shipping in real products from many vendors, and solving real problems.
- There is more to do to make identity systems rich enough for online relationship management.
- Cloud computing is an important concept, a valid trend, and it provides strong use cases for multi-domain identity systems.
I am left with one question: did the beer taste so good because I was in Germany, or was it just the beer?
 When
When 
 The
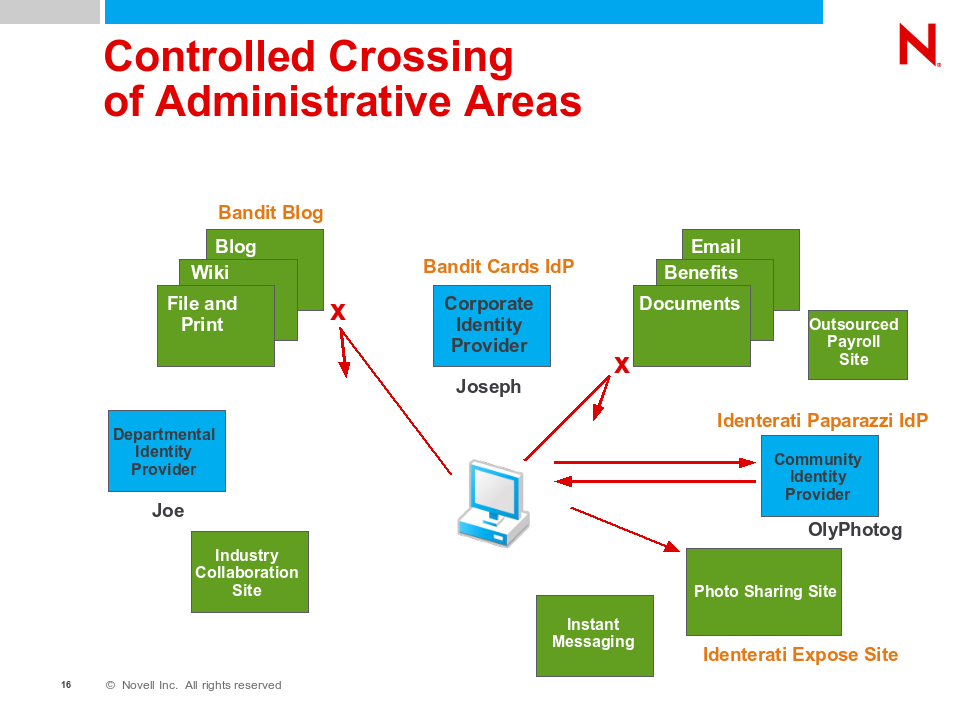
The  For example, managed information cards can be issued in auditing or non-auditing mode. In auditing mode, the identity provider knows who the relying party is and can control if and what data is securely sent to the Relying Party. In non-auditing (or privacy) mode the identity provider does not know where the data is to be sent — and hence cannot audit or change what data is sent based on that knowledge.
For example, managed information cards can be issued in auditing or non-auditing mode. In auditing mode, the identity provider knows who the relying party is and can control if and what data is securely sent to the Relying Party. In non-auditing (or privacy) mode the identity provider does not know where the data is to be sent — and hence cannot audit or change what data is sent based on that knowledge.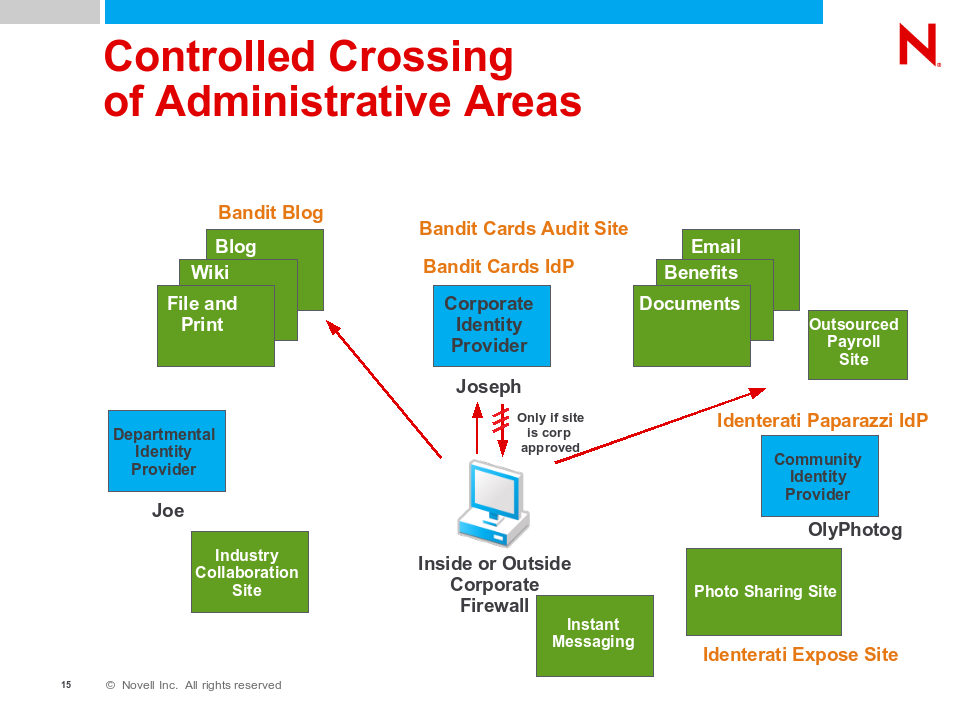
 Along those lines, at Novell’s Brainshare conference there was a panel discussion about “Open Source and User-centric Identity in the Enterprise”. The discussion was moderated by Carolyn Ford, and included Kim Cameron, Pamela Dingle, Patrick Harding, and myself. A
Along those lines, at Novell’s Brainshare conference there was a panel discussion about “Open Source and User-centric Identity in the Enterprise”. The discussion was moderated by Carolyn Ford, and included Kim Cameron, Pamela Dingle, Patrick Harding, and myself. A  For example, information card systems allow for assertions of identity data to be securely transmitted from an authoritative source to a network service in such a way that the user cannot tamper or see the data, yet is a control point for the release of the data.
For example, information card systems allow for assertions of identity data to be securely transmitted from an authoritative source to a network service in such a way that the user cannot tamper or see the data, yet is a control point for the release of the data. All of these perspectives are useful, and they are all useful within the enterprise, outside of the enterprise, and especially when crossing such boundaries.
All of these perspectives are useful, and they are all useful within the enterprise, outside of the enterprise, and especially when crossing such boundaries. A hub is like the proverbial silo. In the case of meta/virtual/directories the problem goes beyond the inflexibility of large identity silos like Yahoo and Google — those silos support a limited set of very tightly coupled applications. In enterprise deployments, many more applications access the same meta/virtual/directory service. As those applications come and go, new versions are added, some departments are unwilling to move, the central service must support the union of all identity data types needed by all those applications over time. It’s not whether the service can technically achieve this feat, it’s more an issue of whether the application administrators are willing to wait for delays caused by the political bottleneck that the central service inevitably becomes.
A hub is like the proverbial silo. In the case of meta/virtual/directories the problem goes beyond the inflexibility of large identity silos like Yahoo and Google — those silos support a limited set of very tightly coupled applications. In enterprise deployments, many more applications access the same meta/virtual/directory service. As those applications come and go, new versions are added, some departments are unwilling to move, the central service must support the union of all identity data types needed by all those applications over time. It’s not whether the service can technically achieve this feat, it’s more an issue of whether the application administrators are willing to wait for delays caused by the political bottleneck that the central service inevitably becomes.
